Adversarial Validation: can i trust my validation dataset?
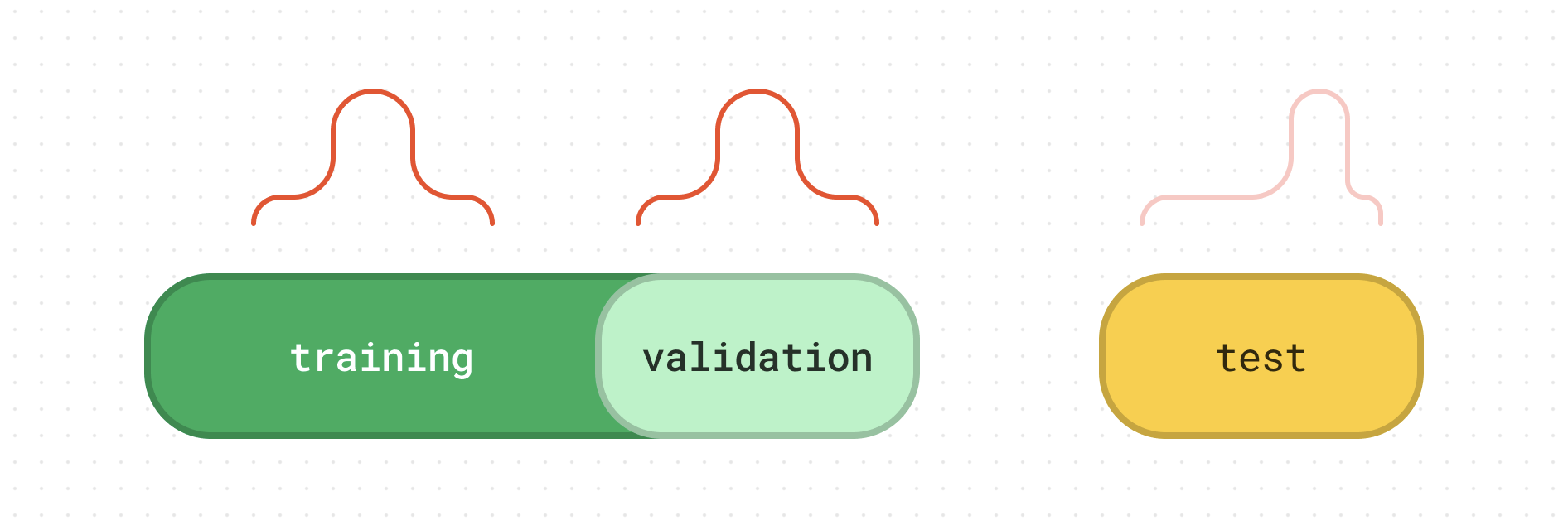
the problem A common workflow in machine learning projects (especially in Kaggle competitions) is: train your ML model in a training dataset. tune and validate your ML model in a validation dataset (typically is a discrete fraction of the training dataset). finally, assess the actual generalization ability of your ML model in a “held-out” test dataset. This strategy is widely accepted, as it forces the practitioner to interact with the ever important test dataset only once, at the end of the model selection process - and purely for performance assessment purposes....